Anonymous
0
0
Lý thuyết Tin học 10 Bài 3 (Kết nối tri thức): Một số kiểu dữ liệu và dữ liệu văn bản
- asked 6 months agoVotes
0Answers
0Views
Lý thuyết Tin học 10 Bài 3: Một số kiểu dữ liệu và dữ liệu văn bản
1. Phân loại và biểu diễn thông tính trong máy tính
- Biểu diễn thông tin là cách mã hóa thông tin.
- Các kiểu dữ liệu thường gặp là văn bản, số, hình ảnh, âm thanh và lôgic.
- Việc phân loại dữ liệu để có cách biểu diễn phù hợp nhằm tạo điều kiện thuận lợi cho việc xử lí thông tin trong máy tính.
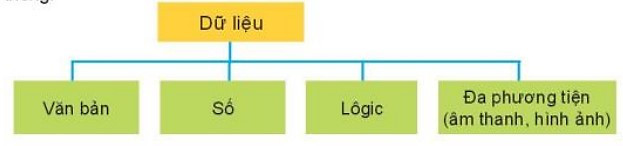
Bảng 1: Sơ đồ phân loại các kiểu dữ liệu
2. Biểu diễn dữ liệu văn bản
a) Bảng mã ASCII
- Ban đầu bảng mã này dùng các mã 7 bit, với 128 mã khác nhau chỉ thể hiện đúng 128 kí tự.
- Bảng mã 7 bit chỉ đủ dùng cho tiếng Anh trong khi nhiều quốc gia dùng kí tự riêng, như Trung Quốc, Hy Lạp, …
⇒ Người ta mở rộng bảng mã 7 bit thành bảng mã 8 bit gọi là ASCII mở rộng cho phép mã hóa 256 kí tự.
b) Bảng mã Unicode và tiếng Việt trong Unicode
- Ngoài các kí tự có trong bảng chữ cái tiếng Anh, Tiếng Việt còn có 134 nguyên âm có dấu thanh và phụ âm “đ” đều không có sẵn trong bảng mã ASCII, trong khi phần mở rộng của bảng mã ASCII lại chỉ có 128 vị trí.
- Tình trạng thiếu vị trí còn trầm trọng hơn với những quốc gia dùng chữ tượng hình như Trung Quốc, Hàn Quốc, …
⇒ Do đó bảng mã Unicode được xây dựng dùng chung cho mọi quốc gia.
- Unicode là một bộ tiêu chuẩn biểu diễn kí tự văn bản trong máy tính, cho phép biểu diễn kí tự thuộc nhiều loại ngôn ngữ khác nhau.
- UTF-8 là hệ thống mã hóa kí tự với độ dài khác nhau dành cho Unicode.
- Từ năm 2017, Việt Nam ban hành quy định bắt buộc sử dụng UTF-8 để biểu diễn các kí tự Tiếng Việt trong máy tính, dùng bảng mã ASCII để mã hóa kí tự latinh không dấu, sử dụng 2 byte để mã hóa các nguyên âm có dấu, các kí tự Đ đ và chỉ dùng 3 byte một số rất ít các kí tự đặc biệt.
c) Số hóa văn bản
- Tệp văn bản là định dạng lưu trữ ở bộ nhớ ngoài.
- Việc số hóa văn bản được thực hiện bằng các phần mềm soạn thảo văn bản như Word, Writer.
- Hiện tại có thể nhập văn bản bằng nhận dạng tiếng nói.